
API
Create an endpoint from a query
Summary
The API component creates a hosted endpoint to fetch data from your persistence and core sim tables. Each time the API endpoint is called, the API will execute a user-defined, pre-populated query; the query can be parameterized, allowing you to pass information from the API request to the query.
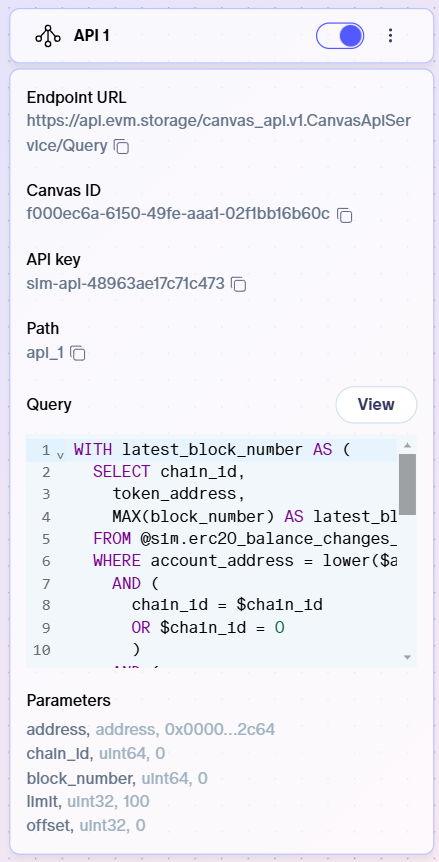
Inputs
- Path: This is the name of the endpoint, which you'll need to provide as part of your request.
- API key: You can specify the API key or leave blank to generate one randomly.
- Query: Hit
Defineto input the query you want to execute. Use $ to define parameters that will be specified in each request. The SQL syntax of our query engine is Apache Calcite. In the API query editor, you can select from and customize templates as well as test your query. - Parameters: You can create query parameters by adding $. Once you add a parameter, you'll be asked to define the type and, optionally, a default value. If a default value is not provided at this state, then the value must be provided in each request to the API.
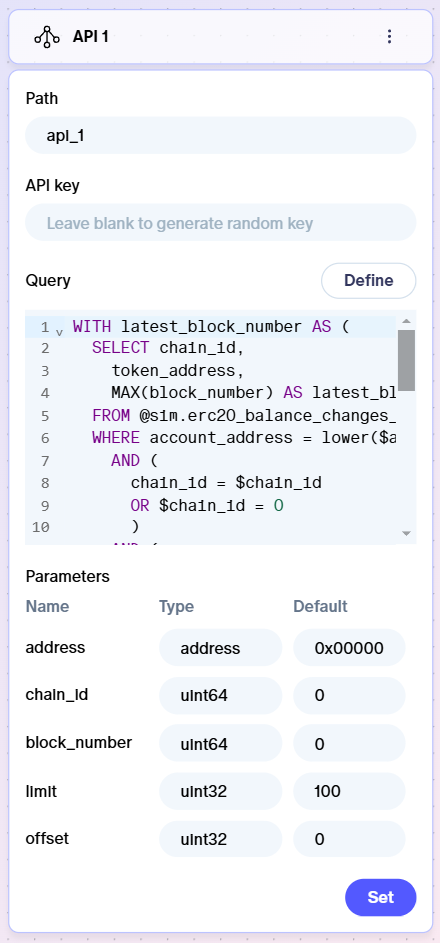
Interactions
Using the three-dot menu, you can see a quick guide, delete or duplicate an API component. Once set, you can also copy a cURL request. You can also test your API query in the API query editor.
Allowed edges
Incoming
- Persistence (optional): In APIs (and queries), you can query against any table from your org, as well as all @sim core tables, regardless of the canvases in which they were created. In some cases where we're querying a persistence we created in the same canvas, we like to add an edge between the two to make the data origin clear, but these edges are purely cosmetic.
Outgoing
- API components do not have any outgoing edges.
Pagination
Limit-offset
Suppose you want to build a REST API that exposes ERC20 balance changes ordered by recency, with the most recent first. You certainly don't want to get all records in one request:
select count(*) from @sim.ethereum_erc20_balance_changes_block
-- returns 2368945472 (2 billion!) as of 2024-06-27But you may want to build a paginated table allowing the API's user to paginate back in time at the user's request. The simplest way to do this is by using OFFSET and LIMIT. Specifying them as optional parameters allows for customization at the time of request:
select * from @sim.ethereum_erc20_balance_changes_block
order by block_number desc, txn_hash
limit $limit offset $offsetSet the default for $limit to the number of records you want in each page. The offset defines the number of items you want to skip. So if you want the second page of a ten-record table, you'd set the offset to 10. More generally, for page n multiply (n - 1) by the limit to get the offset required for that page.
If you want a total page (or record) count, you can easily build a second endpoint to return the result of the count, as we did in the first query, and divide by the limit for the number of pages. This setup allows for a rich and customizable (user-selected page lengths, navigate to last page, etc.) tables.
Continuation tokens
For most applications, the approach above should work well. There are two cases where it won't:
- For larger result sets, it can be inefficient and fail for large offsets / high page numbers because generating the nth pages may require processing data for all pages <n.
- For frequently changing result sets. Suppose while you're looking at a page of ten records, ten new records are prepended above them (in the ordering defined in the query). When you ask for the next page based on the limit/offset, you may find yourself looking at the same data again because what was the first page became the second page.
The two issues share a solution: create a column in your table that serves both as a unique ID on each record and an ordering that will be used for API pagination. In the API request, add a continuation parameter and where <ID> > $continuation to the query. Return the IDs also with each record in the API's response. Then, to get the next page, simply take the ID of the last received result and use it as the continuation parameter in the subsequent API call. This resolves both issues described above. If you need any help setting this up, reach out to us on TG--we're happy to help.
Use uint64, not uint256, for IDsGiven current limitations with using inequality operators with
BIGDECIMALdata in Pinot, it's best to emit this ID from a lambda or shadow contract asuint64(notuint256) so that it flows into Pinot as aLONG.
Array params
You can use arrays as API parameters. To do so, type the parameter you wish to use to pass the array as string. Include it in the query as we've done with $addresses here:
select * from @sim.erc20_balance_changes_block
where account_address in ($addresses)Then, in the test interaction, use this for the value:
[0x2ab1667de20dc3df4f89b89dda81ef7ac8290a37, 0x48d004a6c175db331e99beaf64423b3098357ae7]Note that there are no quotation marks within the array. If you include some, your query will fail.
When cURLing in to the API, pass the array equivalently as a string:
"query_parameters":{"addresses":"[0x2ab1667de20dc3df4f89b89dda81ef7ac8290a37, 0x48d004a6c175db331e99beaf64423b3098357ae7]"}Updated 9 months ago