New features
-
sim Explorer now supports Base 🥳. Check out USDC on Base. Anything you can do with an Ethereum address, you can now also do with a Base address. The Explorer home page is also now multichain.
- Note that we've had Base in sim Studio for ages. See some data you like in Explorer and want to build it in Studio--reach out!
-
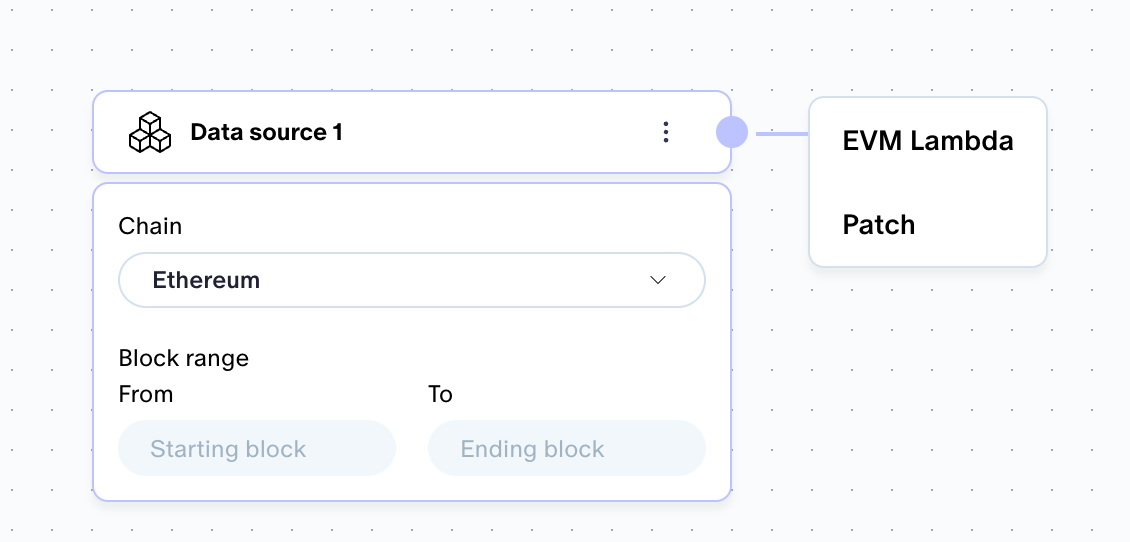
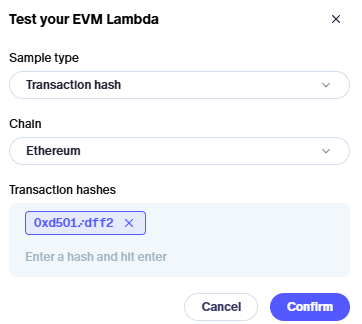
Test EVM Lambda or Patch components on a specific transaction instead of a block range. We were prototyping a traces core table recently (more on this soon!) and running the test interaction even on a single block gave us way more traces than we needed/wanted to spot check. Now you can just give a single transaction hash and test on that, if you prefer.
-
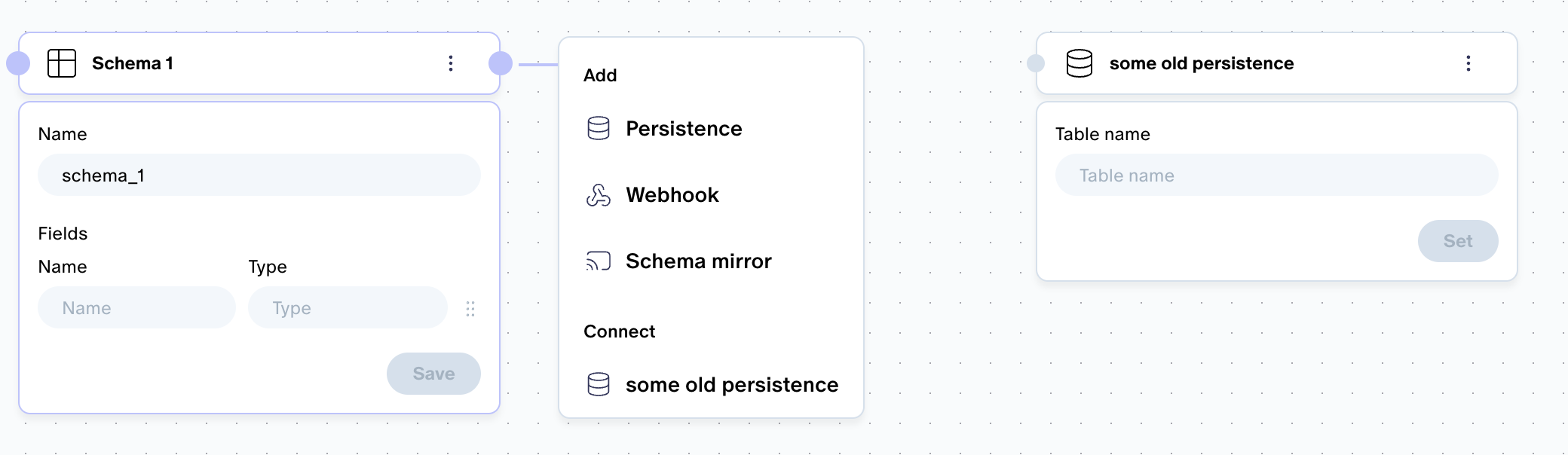
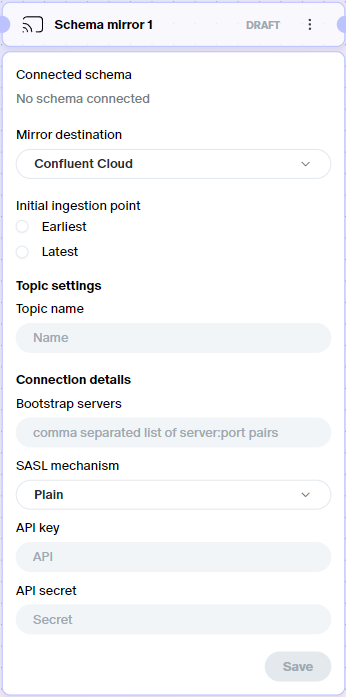
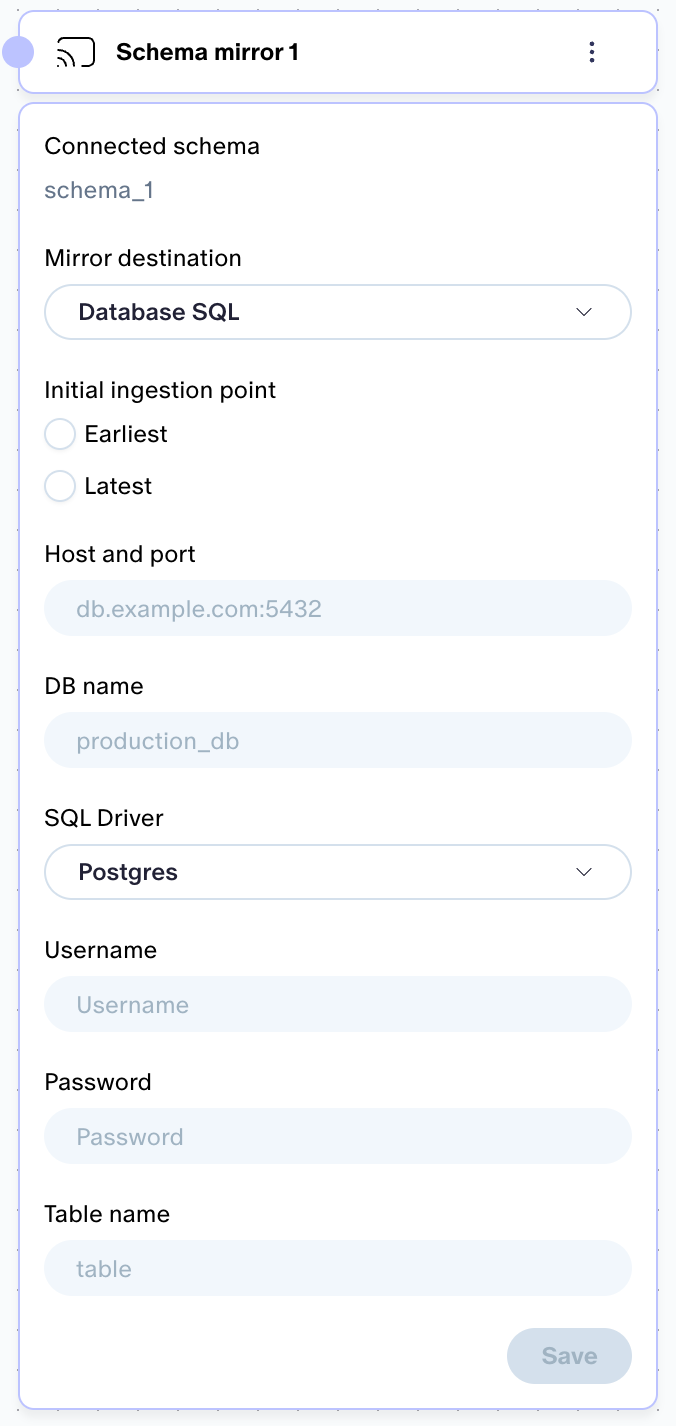
Emitting data directly to Postgres: With the schema mirror, you can mirror sim data to an external Kafka topic and then ingest from there into your preferred DB. If you want to send it to Postgres, you can now skip the Kafka middleman!
-
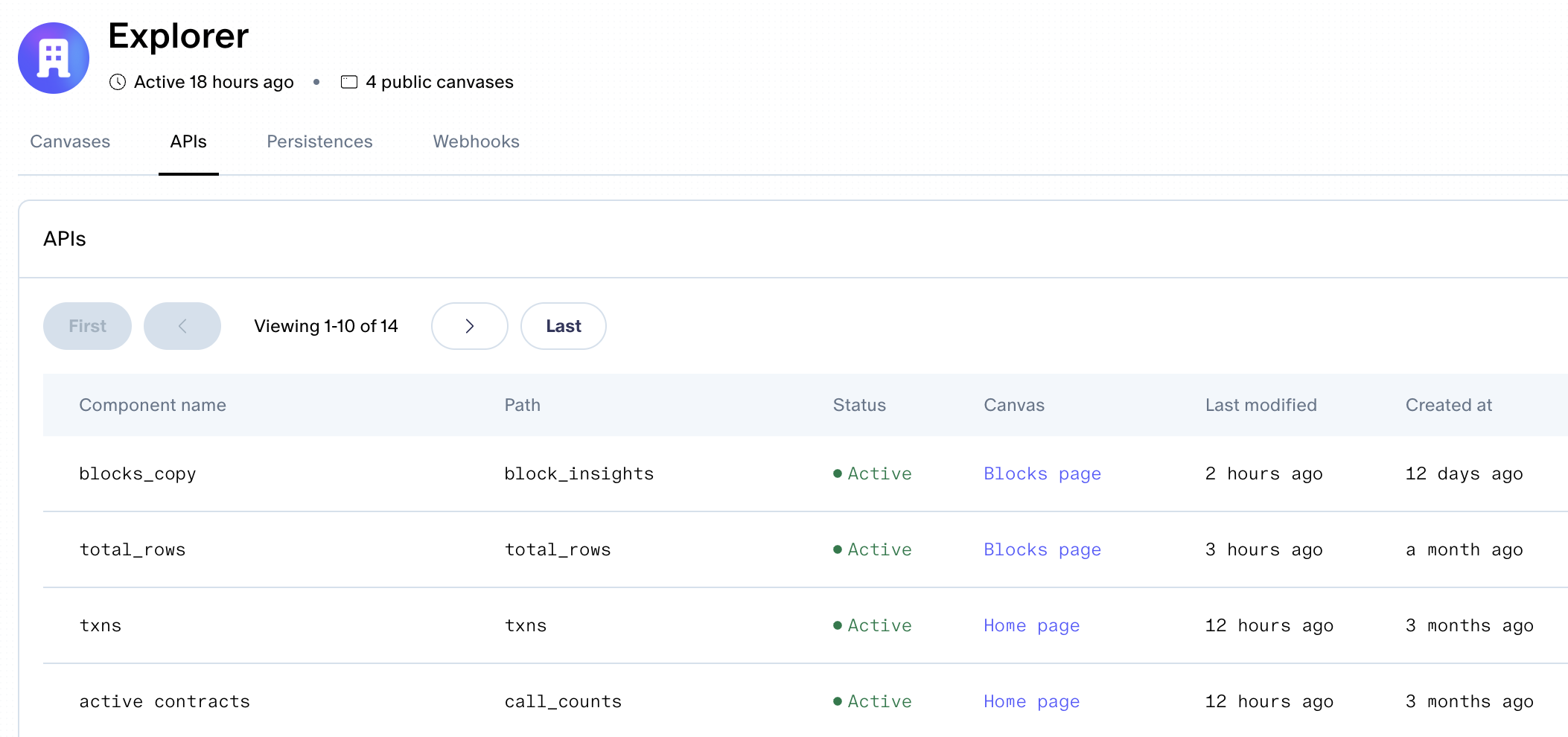
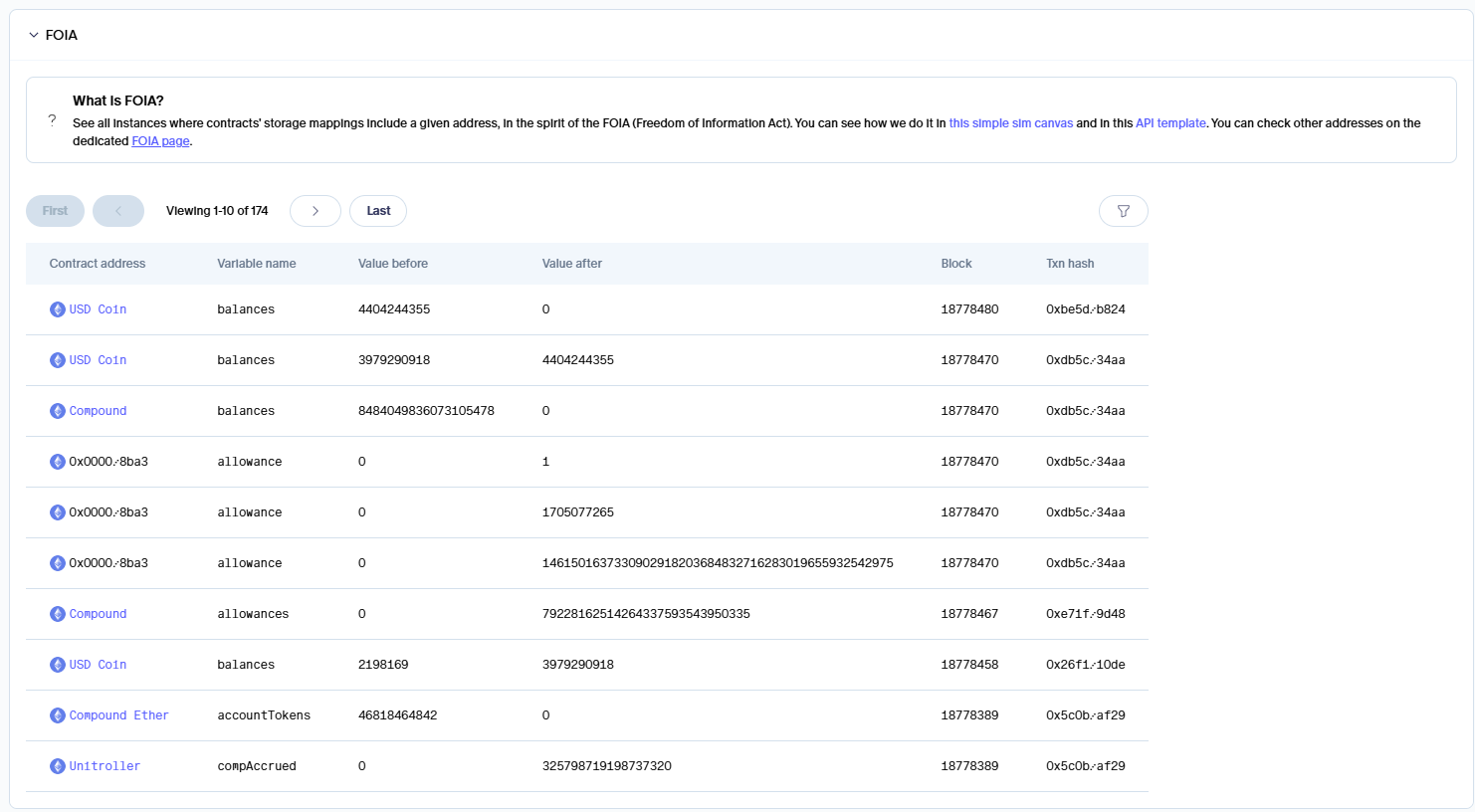
FOIA -> sim Explorer: On EoA pages on Explorer, we have our new Freedom of Information Act (FOIA) component that shows all instances of the given address in mappings in contracts' storage. We also have a dedicated route for just this data at https://explorer.sim.io/foia.
-
Playground dashboards: You may have noticed that we're including some simple dashboards like this dex bot dashboard and this trader PnL one in our X threads. These were created by non-engineer team-members with some AI assistance and we decided to share them at playground.sim.io. Turns out it's not that hard to build a useful FE if you have the right data from sim Studio. Shh! Don't tell our FE engineers I said that!
-
Improved mechanics for query results and lambda/patch logs panes: If you ever had issues with pane sizing within the Query Editor or IDE, e.g., your SQL got stuck underneath the query results, please accept our sincere apologies. Our custom logic turned out to be less than ideal. We're now using a library built for this. If you see something wrong, let us know.