
Auto-generated schemas, mirrors, API templates, and block filters
July 1st, 2024
New features
- Auto-generated schemas: When you're adding a hook in a lambda, you can choose to automatically generate and populate a corresponding schema. This means your lambdas will be fully testable, and in some cases ready to be deployed for backfills, without you having to write any Solidity at all.
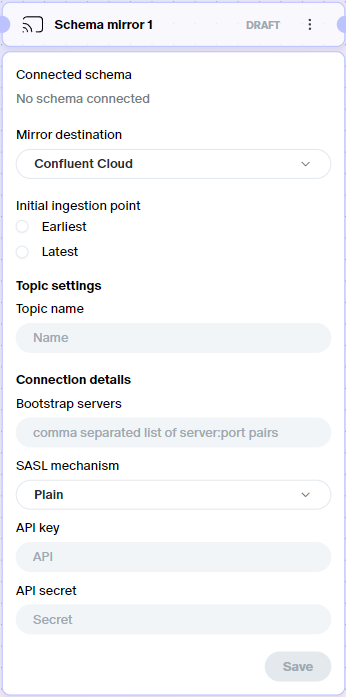
- Schema mirrors: You can now mirror data from a sim schema component into your own Generic Kafka or Confluent Cloud topic. Create the destination topic first, then create a new
Schema mirrorcomponent in you canvas, connect it to an existing schema component, and point it at the destination topic.
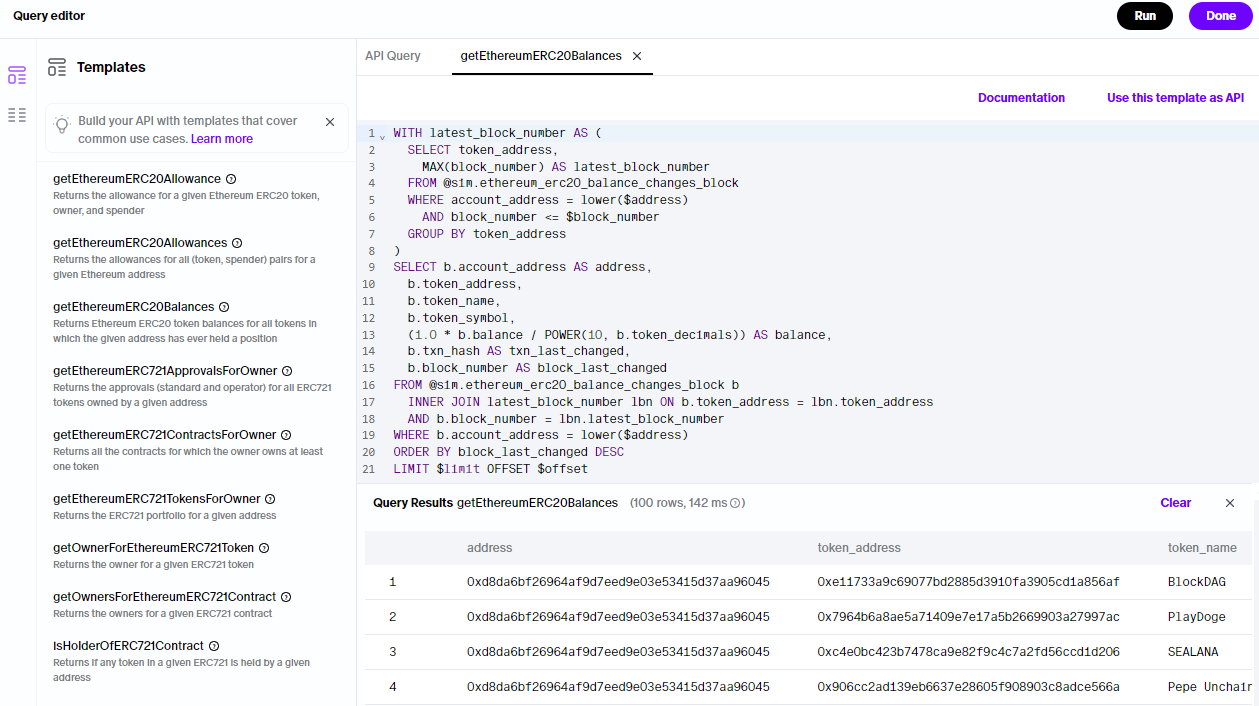
- API templates: We've been building core tables to make it easier for you to serve common query/API patterns without having to build the data yourself in a lambda. We're now going further in this direction by providing API templates on top of them. When defining an API query, explore the templates via the sidebar, run them, and choose
Use this template as APIto insert a template into theAPI Querytab. If it's exactly what you want, great. If not, customize it to your specific requirements.
- Block filters for faster backfill: Sometimes when you do a backfill execution for your lambda, there are very few blocks within the block range in which the hooks actually intercept executions. Previously we'd still execute all blocks in the block range despite this, but now we have filters so that we'll only execute blocks relevant to your lambda. As a result, backfills are much faster, especially on sparser hooks. We're still improving how the filters work for more active contracts.
Improvements and bug fixes
- You can now manually define the API key for API components, both at initial setup and in subsequent edits.
- Query params used to reset whenever the query was changed at all, and when execution of the query failed. We've made them much stickier.
Coming soon
- Open alpha: We're preparing to remove the waitlist and move to an open alpha. We'll be limiting certain features for new users. As part of this effort, we're also beefing up our execution and DB infra, which should result in a more performant and consistent experience for existing users.
- Stateful lambdas: Currently any state you generate within a lambda gets reset every block. This is usually very nice as it means we can safely parallelize backfills, and aggregations can be done downstream or at query time. For some use cases, however, calculating and adjusting aggregations across blocks within the lambda’s state is very powerful, so we're launching a stateful version of the EVM lambda in the near future. These may be more costly to run and won’t backfill as fast, but they're extremely powerful for specific use cases.
- A new patched contract component (as mentioned last changelog).